Gradient Boosting
Contents
Gradient Boosting#
The gradient is back!
Core concept#
Contrary to AdaBoost, which builds another decision stump based on the errors made by the previous decision stump, Gradient Boosting starts by making a single leaf. This leaf represents an initial guess (round 0). Next, a first tree is made, outputting a first round of predictions (round 1). Then the pseudo-residuals are calculated. They are residuals, in the sense that they are the difference, for each training sample, between the predicted class and the observed class. We will see how this is computed from a binary output to a probability soon. The key concept behind Gradient Boosting is that the next tree fits the residuals of the previous one. In this sense, Gradient Boosting is performing a gradient descent, the residuals giving the step direction to go to minimize the errors and thus improve the prediction’s accuracy. Final predictions are made by ‘summing the trees’ (times a learning rate) and converting the final number into a probability for a given class.
We will go through an example with a very small dataset to understand the steps and calculations.
A minimal example#
Let’s say we have a dataset of simulated training samples of collisions and for each collision some features such as an invariant mass and missing transverse energy (these variables will be explained during tutorials). We want to use Gradient Boosting to search for new physics. This new physics process is simulated in signal samples (target \(y=1\)) and background processes, i.e. interactions from known physics processes but mimicking the signal outputs, are with \(y=0\).
Row |
\(m_{bb}\) |
MET |
… |
Class |
|---|---|---|---|---|
0 |
60 |
35 |
… |
0 |
1 |
110 |
130 |
… |
1 |
2 |
45 |
78 |
… |
0 |
3 |
87 |
93 |
… |
0 |
4 |
135 |
95 |
… |
1 |
5 |
67 |
46 |
… |
0 |
Step 0: Initial Guess
We start by an initial guess. In Gradient Boosting for classification, the initial prediction for every samples is the log of the odds. It is an equivalent of the average for logistic regression:
Here we have 2 signal events and 4 background ones, so log(odds) = \(\log \frac{2}{4}\) = -0.69
How to proceed now with classification? If you recall logistic regression, the binary outcomes were converted as an equivalent of a probability with the logistic function (sigmoid). We will use it again here:
In our example, \(\frac{1}{1 + e^{ - \log \frac{2}{4} }} = \frac{1}{3}\).
Step 1: pseudo residuals
Now let’s calculate the pseudo residuals.
Definition 54
Pseudo residuals are intermediate errors terms measuring the difference between the observed values and an intermediate predicted value.
We will store pseudo residuals as an extra column. For the first row (index 0), the pseudo residual is \(( 0 - \frac{1}{3}) = -\frac{1}{3}\). The second, with observed value 1, is \(( 1 - \frac{1}{3}) = \frac{2}{3}\).
Row |
\(m_{bb}\) |
MET |
… |
Class |
Residuals |
|---|---|---|---|---|---|
0 |
60 |
35 |
… |
0 |
-0.33 |
1 |
110 |
130 |
… |
1 |
0.67 |
2 |
45 |
78 |
… |
0 |
-0.33 |
3 |
87 |
93 |
… |
0 |
-0.33 |
4 |
135 |
95 |
… |
1 |
0.67 |
5 |
67 |
46 |
… |
0 |
-0.33 |
Step 2: tree targeting the pseudo residuals
Now let’s build a tree using the input features but to predict the residuals.
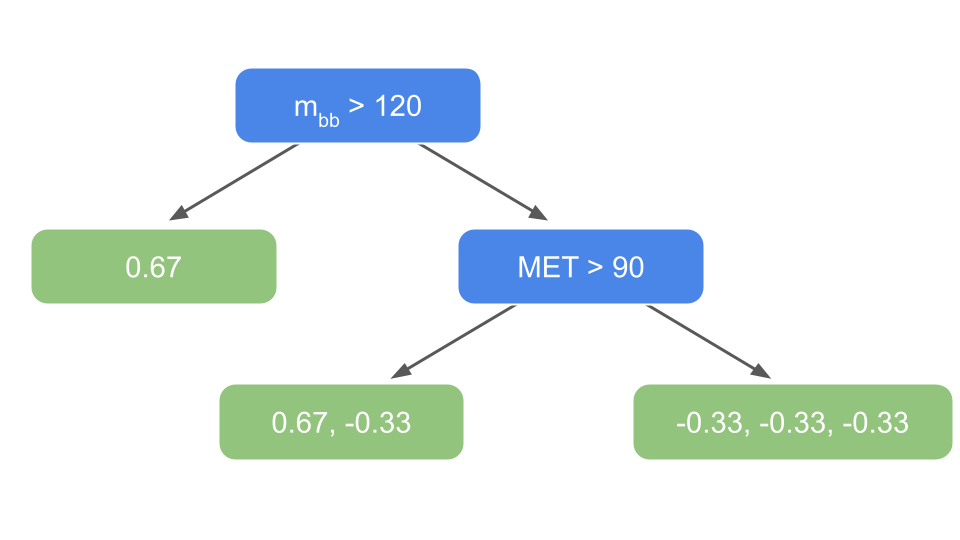
Fig. 29 . First tree predicting the residuals.
Image from the author#
The tree is very minimal because we only have six samples in the dataset! Usually there can be up to 32 leaves in Gradient Boosting intermediary trees.
Step 3: leaves’ output values
The predictions are in terms of the log of the odds, whereas leaves are derived from a probability. We will have to translate the residuals in the leaves above as “log of the odds” first. Only after getting the correct leave outputs can we combine trees together. When using Gradient Boost for classification, the most common transformation is the ratio:
The numerator is the sum of residuals in a given leaf \(i\). The denominator is the product of the previously predicted probabilities for each residual in that same leaf \(i\). Let’s illustrate with our example. For the leaf on the very left, there is only one residual (from sample row 4) of 0.67 with an associated probability of \(\frac{1}{1 + \exp( - \log \frac{2}{4} )} = \frac{1}{3}\). So:
The new output value for the leaf is 3. Now the second leaf from the left has two samples in it: rows 1 and 3. The former is signal, with a residual of \(\frac{2}{3}\) and an associated (previous) probability of \(\frac{1}{3}\), whereas the latter is a background sample with a residual of \(-\frac{1}{3}\) and associated probability of \(\frac{2}{3}\).
For the last leaf, we have:
The tree has now output values:
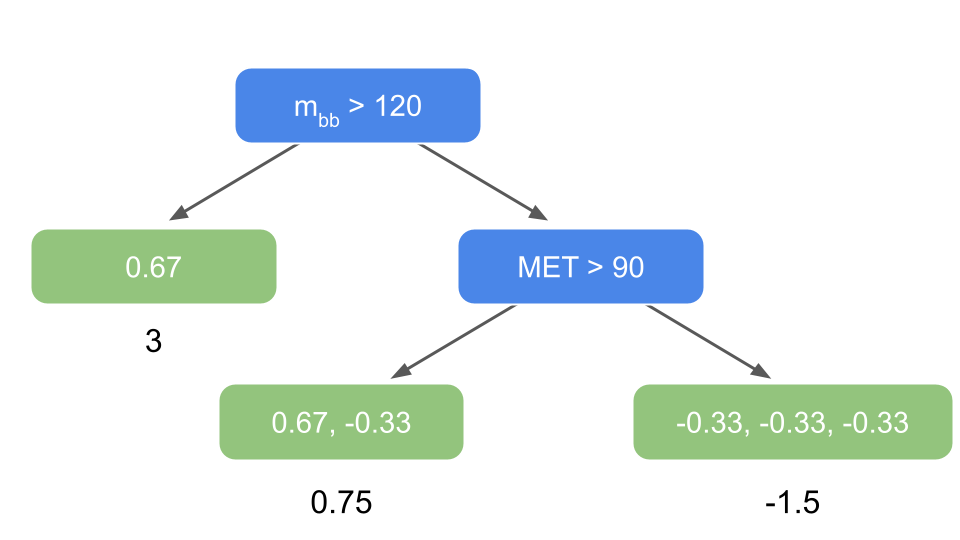
Fig. 30 . First tree predicting the residuals with output values for each leaves as ‘predictions’ (log of odds).
Image from the author#
Step 4: update predictions
The first tree targeting the residuals is combined with the initial guess:
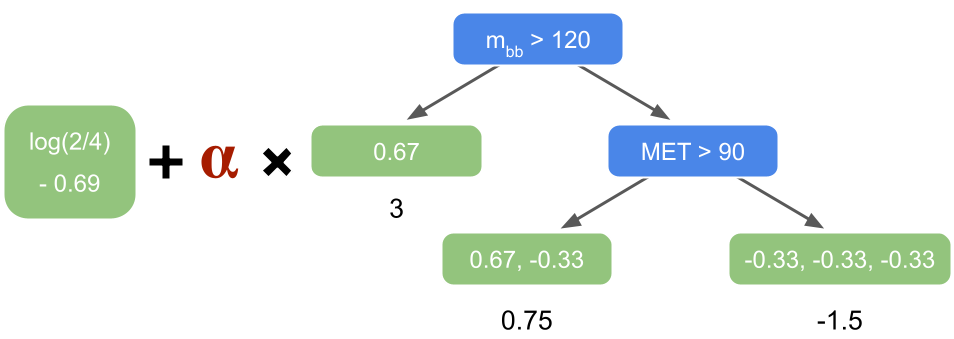
Fig. 31 . The initial guess and the first tree are combined. The tree is scaled by a learning rate \(\alpha\).
Image from the author#
Usually the learning rate is around 0.1 but for simplicity here in our example, we will take a larger value of \(\alpha = 0.5\) (to get a more drastic change after only two rounds). The first row of index 0 falls into the right leaf. To calculate the new log of the odds prediction for row 0, we sum the initial guess with the learning rate times the leaf output (expressed as a log of the odds from the calculation above):
Now we convert the new log of the odds as a probability:
As this row 0 is a background event, we went from an initial guess of probability \(\frac{1}{3}\) to now 0.20, which is closer to zero, so our first residual-fitted-tree added a correction in the right direction. Let’s take row 1 now. It lands in the middle leaf. Thus:
The probability is:
The event is signal, so our prediction should be close to 1. We went from an initial guess probability of \(\frac{1}{3}\) to 0.42. We indeed go in the right direction! Smoothly, but surely.
Note
It has been shown empirically that a slow learning rate is preferable to reach a good accuracy. It comes at the price of having to build numerous intermediary trees incrementing the predictions in small steps. Without a learning rate scaling the trees, there is a high risk to stay too close to the data, which would bring a low bias but very high variance. Thanks to a small learning rate, taking lots of small steps in the right direction results in better predictions with a testing dataset. This technique is called shrinkage.
We can add an extra column with the predicted probabilities (pred prob) in our dataset table:
Row |
\(m_{bb}\) |
MET |
… |
Class |
Residuals |
Pred Prob |
|---|---|---|---|---|---|---|
0 |
60 |
35 |
… |
0 |
-0.33 |
0.19 |
1 |
110 |
130 |
… |
1 |
0.67 |
0.42 |
2 |
45 |
78 |
… |
0 |
-0.33 |
0.19 |
3 |
87 |
93 |
… |
0 |
-0.33 |
0.42 |
4 |
135 |
95 |
… |
1 |
0.67 |
0.69 |
5 |
67 |
46 |
… |
0 |
-0.33 |
0.19 |
We can see that the predicted probabilities for background went towards zero, whereas those for signal got incremented towards 1.
Step 2bis: new pseudo residuals We go back to step 2 to compute the new pseudo residuals from the last set of predictions. Then the step 3 will consist of building a second tree targeting those new residuals. Finally, one we have all the output values for the resulting tree leaves, we can add the second tree to the initial guess and the first tree (also scaled with the learning rate).
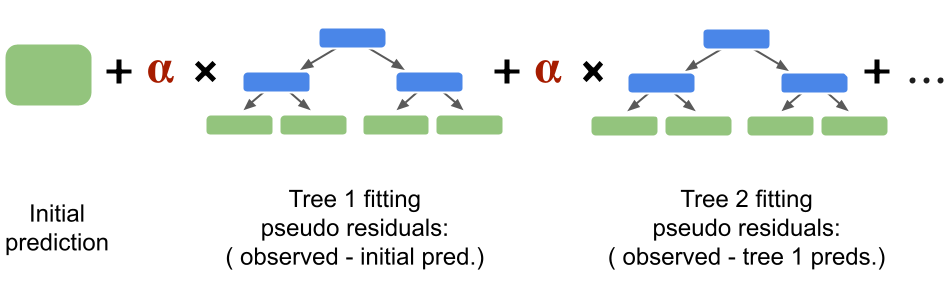
Fig. 32 . The Gradient Boosting sums the trees fitting the pseudo residuals from the previous predition.
Image from the author#
The process repeats until the number of predictors is reached or the residuals get super small.
Predictions on test samples#
How are predictions made on new data? By simply using the sum above. We run the new sample in the first tree, get the output value of the leaf in which the sample ends up, then run it through the second tree, get the final leaf output value as well. The final prediction is done computing the sum with the initial prediction and each tree prediction scaled by the learning rate. If it is greater than 0.5, the class is signal: \(y^\text{pred} = 1\). If lower, we predict the sample to be background.
Code implementation#
Scikit-Learn has two classes implementing Boosting: GradientBoostingRegressor (for regression, see below some links covering it if you are curious) and GradientBoostingClassifier. The latter supports multi-class classification. The main hyperparameters are the number of estimators n_estimators (how many intermediary trees are built) and the learning_rate \(\alpha\).
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
# Getting the dataset [sample loading not shown]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creating the Gradient Boosting (GB) classifier:
gb_clf = GradientBoostingClassifier(
n_estimators=100,
learning_rate=1.0, # no shrinkage here, otherwise 0.1 is a common value
max_depth=1, # here decision stumps
random_state=0)
gb_clf.fit(X_train, y_train)
# Printing score (accuracy by default)
gb_clf.score(X_test, y_test)
The size of each intermediate tree can be controlled by max_depth (it is rarely a stump, rather a tree of depth 2 to 5) or max_leaf_nodes. There are different log functions available, the log-loss being the default.
Note
The classes above have been superseeded by HistGradientBoostingRegressor and HistGradientBoostingClassifier. They are inspired by the framework LightGBM for Light Gradient Boosting Machine, developed by Microsoft. Histogram-based estimator will run orders of magnitude faster on dataset larger than 10,000 samples. More information on Scikit-Learn Historgram-Based Gradient Boosting.
XGBoost the warrior#
XGBoost, for eXtreme Gradient Boosting, is a software library offering a fully optimized implementation of gradient boosting machines, focused on computational speed and model performance. It was created in 2016 by Tianqi Chen, at the time Ph.D. student at the University of Washington. XGBoost gained significant popularity in the last few years as a result of helping individuals and teams win virtually every Kaggle structured data competition, and in particular the first Higgs Boson Machine Learning Challenge.
In terms of model features, XGBoost has the standard Gradient Boosting, as well as a Stochastic Gradient Boosting (more on this in Section Stochastic Gradient Descent) and a Regularized one (with both L1 and L2 regularization methods).
It has also system features. Parallelization (to efficiently construct trees using all available CPU cores), Distributed Computing (if working with a cluster of machines), Out-of-Core Computing (when very large datasets can’t be loaded entirely in the memory), Cache Optimization (to minimize the need to access data in underlying slower storage layers).
The algorithm features contains some technical jargon. Here is a selection of the main ones with some explanations:
Sparsity Awareness
Data is considered sparse when certain expected values in a dataset are missing, or with mostly the same value, which is a common phenomenon in general large scaled data analysis. This can alter the performance of machine learning algorithms. XGBoost handles sparsities in data with the Sparsity-aware Split Finding algorithm that choose an optimal direction in the split, where only non-missing observations are visited.
Block Structure
Data is sorted and stored in in-memory units called blocks, enabling the data layout to be reused by subsequent iterations instead of computing it again.
Continued Training
XGBoost makes it possible to further boost an already fitted model on new data, without having to reload everything.
Here is a minimal example of implementation in Python as well as other languages.
Exercise
It is always good to ‘go to the source,’ i.e. the original papers. Yet this can be over-technical and daunting.
Here is the paper of XGBoost on the arXiv platform:
Chen & Guestrin, XGBoost: A Scalable Tree Boosting System (2016)
To make it more enriching and fun, dive into the paper with a classmate. After each section, take turns to explain to your peer what you understand with your own words. This will train you to read the literature in the future, be confronted to different mathematical notations and digest the content (papers are usually dense in information, so don’t worry if it takes you time to go through one).
In the tutorial, we will classify collision data from the Large Hadron Collider using decision trees, then a random forest and finally boosted classifiers. We will compare their performance with the metrics introduced in Lecture Performance Metrics.
Modern boosting libraries: LightGBM and CatBoost#
After the success of XGBoost in the mid-2010s, new open-source libraries emerged to modernize and extend gradient boosting. The two most popular are LightGBM and CatBoost.
LightGBM was released in 2017 and initially developed by Microsoft. Its main difference lies in how trees are grown. In XGBoost, all nodes at a given depth are split before moving to the next level, producing balanced trees. This is called level-wise growth. LightGBM, however, looks for the single leaf that reduces the loss the most and splits only that one. This creates deeper trees in “important” regions of the feature space, which can capture more structure with fewer splits. This strategy is called leaf-wise growth. It tends to be more accurate but also more prone to overfitting if depth is not constrained.
LightGBM was designed for efficiency and scalability. It uses histogram-based feature binning: instead of considering all possible split points in a continuous feature, it buckets values into bins (storing bin indices instead of raw values for extra speed). Combined with its leaf-wise growth strategy, the algorithm trains faster and uses less memory on large datasets.
CatBoost is another widely used library, developed by Yandex and also released in 2017. Its focus is on handling categorical data with minimal preprocessing. Normally, boosting libraries require converting categorical variables into numbers (e.g. one-hot encoding), which can inflate dimensionality and sometimes leak information. CatBoost instead uses an approach called ordered target statistics: for each category, it computes statistics (like the mean label value) using only previous training examples, in a random order. This way, the encoding never “sees the future,” avoiding target leakage.
Together with symmetric tree structures and an “ordered boosting” scheme, CatBoost often works very well out of the box, particularly for datasets with many categorical features.