Splitting Datasets for Evaluation
Contents
Splitting Datasets for Evaluation#
Training, Validation, and Test Sets#
In supervised machine learning, we have access to data containing labels, i.e. the input features have associated targets. Whether it is regression or classification, we know the answer. To assess how the model will deal with new cases, we need to compare its predictions with the answers. We cannot perform this comparison if we don’t have the labels! To cope, the input data set is split into different data subsets, each corresponding to a step in the optimization workflow:
Definition 23
The training set is a subset of the input data dedicated to the fitting procedure to find the model parameters minimizing the cost function (step 1).
The validation set is used to assess the performance of the model and tune the model’s hyperparameters (step 2).
The model is iteratively trained using only the training set, then validated using only the validation set until a given satisfying performance is achieved.
The test set is the final assessment done on the model; the resulting error rate on the test set is called generalization error, an estimate on the errors for future predictions with new data samples (step 3).
The general split between the training, validation and test subsets is 60%, 20% and 20% respectively. But depending on the number of samples, a smaller test set is sufficient. Reducing it allows for an increase of the training and validation set sizes, exposing the model to more data samples for training and validation.
Warning
The terms validation and test are sometimes interchangeably used both in industry and in academia, creating some terminological confusion. What is important to keep in mind is that once the iterative back-and-forth of steps 1 and 2 are giving a most performing model, the hyperparameters of the model are frozen and the last check, step 3, is done on not-yet-seen data with those hyperparameters.
TL;DR: Never use the final test data for tuning.
Data sets are split randomly, by shuffling the data rows and cutting and taking the table indices corresponding to the relative split between the three sub-collections. But precious information is lost by not training on the entire data samples available. Moreover, one of the subset could pick more random outliers or noisy features that will deteriorate either the training or validation outcomes. To cope with this, we use “cross-validation.”
Cross-validation#
A commonly used technique is to use the training set as validation set and vice versa, then pick the best performing outcome (set of hyperparameters). For instance if the entire data sample is split in terms of train/validate/test as A/B/C/D, with D the final test set, the cross-validation would consist of:
training with sets (BC) and validate with set A
training with sets (CA) and validate with set B
training with sets (AB) and validate with set C
In this example, we have a train/validate split of three sub-sets, we talk of a 3-fold cross-validation. The general name with \(k\) sub-sets is \(k\)-fold cross-validation.
Definition 24
The \(\mathbf{k}\)-fold cross-validation is a procedure consisting of using \(k\) subsets of the data used for the training and validation steps where each subset is rotationally used as the validation set, while the \(k-1\) other subsets are merged as one training set.
The \(k\) validation results are combined to provide an estimate of the model’s predictive performance.
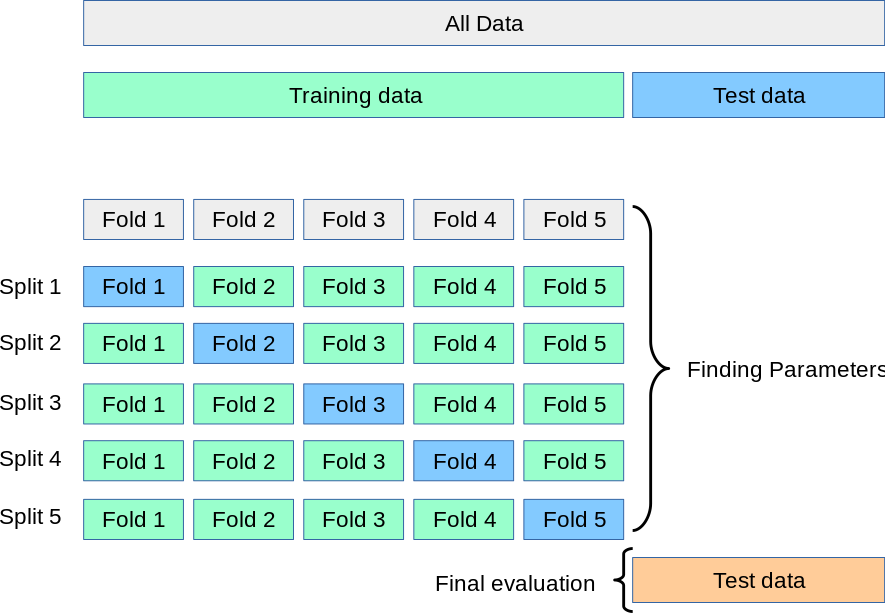
Fig. 15 : Illustration of the \(k\)-fold cross-validation on the training dataset.
Source: Scikit-Learn#
With \(k\)-fold cross-validation, the estimate of the model’s predictive performance comes with a precision (the standard deviation from the collection of \(k\) estimates). However cross-validation necessitates more computing time. Yet it is more robust against noise or outliers picked by the random splitting.
We now know how to manipulate our data set to get an estimate of performance. But how to quantify the performance of a model? And how to visualize it?