AdaBoost
Contents
AdaBoost#
AdaBoost is short for Adaptative Boosting. It works by assigning larger weights to data samples misclassified by the previous learner. Let’s see how this work.
Algorithm#
Pseudocode#
Algorithm 4 (AdaBoost)
Inputs
Training data set \(X\) of \(m\) samples
Outputs
A collection of decision boundaries segmenting the \(k\) feature phase space.
Initialization
Each training instance \(x^{(i)}\) is given the same weight
Start
For each predictor \(t = 1 , \dots , N^\text{pred}\)
a. Train on all samples and compute the weighted error rate \(r_t\)
b. Give the predictor \(t\) a weight \(W_t\) measuring accuracy
\(W_t\) points to a high number if the predictor is good, zero if the predictor is guessing randomly, negative if it is bad. \(\alpha\) is the learning rate.
c. Update the weights of all data samples:
d. Normalize the weights
Exit conditions
\(N^\text{pred}\) is reached
All data sample are correctly classified (perfect classifier)
A visual#
The illustration below gives a visual of the algorithm.
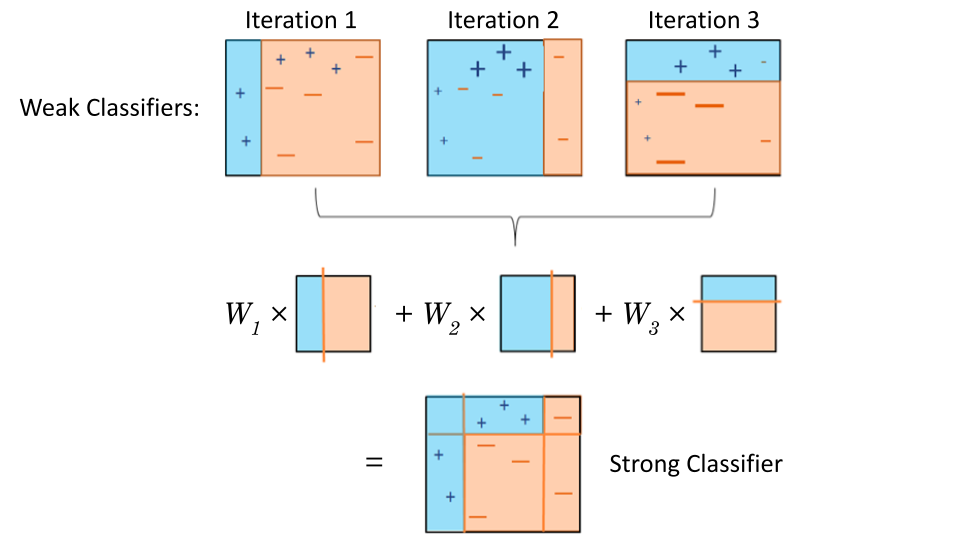
Fig. 28 . Visual of AdaBoost.
Misclassified samples are given a higher weight for the next predictor.
Base classifiers are decision stumps (one-level tree).
Source: modified work by the author, originally from subscription.packtpub.com#
Note
As the next predictor needs input from the previous one, the boosting is not an algorithm that can be parallelized on several cores but demands to be run in series.
How does the algorithm make predictions? In other words, how are all the decision boundaries (cuts) combined into the final boosted learner?
Combining the predictors’ outputs#
The combined prediction is the class obtaining a weighted majority-vote, where votes are weighted with the predictor weights \(W_t\).
The argmax operator returns the value of its argument that maximizes a given function. The expression in square brackets acts as an indicator, counting 1 if the condition is true and 0 otherwise. For each class \(k\), we sum over all predictors \(t\). The predicted class is the one with the largest weighted sum.
Implementation#
In Scikit-Learn, the AdaBoost classifier can be implemented this way (sample loading not shown):
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1),
n_estimators=200,
algorithm="SAMME.R",
learning_rate=0.5)
ada_clf.fit(X_train, y_train)
The decision trees are very ‘shallow’ learners: only a root note and two final leaf nodes (that’s what a max depth of 1 translates to). But there are usually a couple of hundreds of them. The SAMME acronym stands for Stagewise Additive Modeling using a Multiclass Exponential Loss Function. It’s nothing else than an extension of the algorithm where there are more than two classes. The .R stands for Real and it allows for probabilities to be estimated. The predictors need the option predict_proba activated, otherwise it will not work. The predictor weights \(W_t\) can be printed using ada_clf.estimator_weights_.
References#
Learn more
AdaBoost, Clearly Explained - StatQuest video on YouTube
Multi-class AdaBoosted Decision Trees from scikit-learn.org