Feedforward Propagation
Contents
Feedforward Propagation#
What is Feedforward Propagation?#
It is a first step in the training of a neural network (after initialization of the weights, which will be covered in the next lecture). The forward direction means going from input to output nodes.
Definition 56
The Feedforward Propagation, also called Forward Pass, is the process consisting of computing and storing all network nodes’ output values, starting with the first hidden layer until the last output layer, using at start either a subset or the entire dataset samples.
Forward propagation thus leads to a list of the neural network predictions for each data instance row used as input. At each node, the computation is the key equation (48) we saw in the previous Section Model Representation, written again for convenience:
But there will be some change in the notations. Let’s define everything in the next subsection.
Notations#
Let’s say we have the following network with \(x_n\) input features, one first hidden layer with \(q\) activation units and a second one with \(r\) activation units. For simplicity, we will choose an output layer with only one node:
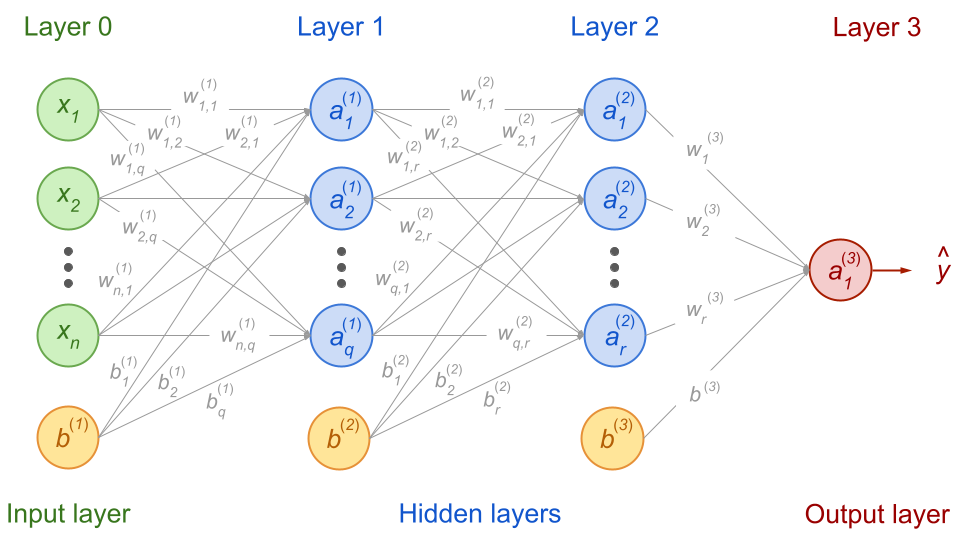
Fig. 53 . A feedforward neural network with the notation we will use for the forward propagation equations (more in text).
Image from the author#
There are lots of subscripts and upperscripts here. Let’s explain the conventions we will use.
Input data
We saw in Lecture 2 that the dataset in supervised learning can be represented as a matrix \(X\) of \(m\) data instances (rows) of \(n\) input features (columns). For clarity in the notations, we will focus for now on only one data instance, the \(i\)th sample row \(\boldsymbol{x^{(i)}} = ( x_1, x_2, \cdots, x_n)\). And we will omit the \((i)\) upperscript for now.
Activation units
In a given layer \(\ell = 1, 2, \cdots, N^\text{layer}\), the activation units will give outputs that we will note as a row vector
where the upperscript is the layer number and the subscript is the row of the activation unit in the layer, starting from the top.
Biases
The biases are also row vectors, one for each layer it connects to and of dimension the number of nodes in that layer:
If the last layer is only made of one node like in our example above, then \(b\) is a scalar.
Weights
Now the weights. You may see in the literature different ways to represent them. In here we use a convention we could write as:
In other words, the first index is the row of the node from the previous layer (departing node of the weight’s arrow) and the second index is the row of the node from the current layer (the one the weight’s arrow points to). For instance \(w^{(2)}_{3,1}\) is the weight from the third node of layer (1) going to the first node of layer (2).
We can actually represent each weight from layer \(\ell -1\) to layer \(\ell\) as a matrix \(W^{(\ell)}\). If the previous layer \(\ell -1\) has \(n\) nodes and the layer \(\ell\) has \(q\) activation units, we will have:
Let’s now see how we calculate all the values of the activation units!
Step by step calculations#
Computation of the third hidder layer#
With one output node, it is actually simpler than for the hidden layers above. We can still write it in the same form as Equation (61):
with \(\boldsymbol{a^{(2)}} = (a^{(2)}_1, a^{(2)}_2, \cdots, a^{(2)}_r)\) that we calculated above.
In our case \(\boldsymbol{a^{(3)}}\) has only one element: \(a^{(3)}_1 = y\).
The matrix \(W^{(3)}\) has only one column.
The bias ‘vector’ is actually a scalar: \(b^{(3)}\).
That’s the end of the forward propagation process! As you can see, it contains lots of calculations. And now you may understand why activation functions that are simple and fast to compute are preferrable, as they intervene each time we compute the output of an activation unit.
Let’s now generalize this with a general formula.
General rule for Forward Propagation#
If we rewrite the first layer of inputs as:
then we can write a general rule for computing the outputs of a fully connected layer \(\ell\) knowing the outputs of the previous layer \(\ell\) (which become the layer \(\ell\)’s inputs):
This is the general rule for computing all outputs of a fully connected feedforward neural network.
Summary#
Feedforward propagation is the computation of the values of all activation units of a fully connected feedforward neural network.
As the process includes the last layer (output), feedforward propagation also leads to predictions.
These predictions will be compared to the observed values.
Feedforward propagation is a step in the training of a neural network.
The next step of the training is to go ‘backward’, from the output error \(\hat{y}^\text{pred} - y^\text{obs}\) to the first layer to then adjust all weights using a gradient-based procedure. This is the core of backpropagation, which we will cover at the next lecture.
Learn More
Very nice animations here illustrating the forward propagation process.
Source: Xinyu You’s course An online deep learning course for humanists